Riverbed Steelhead Transaction Prediction
Sedikit materi dari Training Riverbed Steelhead, materinya untuk ujian RCSA-W, jadi memang hanya sebagai dasar teori dan praktik hands-on.
Pemasangan Steelhead bersifat transparan, jadi tanpa perubahan pada network. Jika appliance mati, maka data seakan di pass through (dilewatkan tanpa diproses). Memiliki fitur Auto Discovery, SH akan mencari lawannya sendiri tanpa harus dikonfigurasi, jika tidak ada lawan, maka data akan di pass through saja tanpa dioptimasi. Membuat koneksi TCP baru pada tiap session yang diminta. Tidak ada tunnel pada riverbed.

Hal ini dilakukan dengan tetap memelihara koneksi TCP yang sudah ada dan membuat sesi TCP sendiri melalui WAN. Dengan ini memungkinkan antara server dan client berkomunikasi seperti biasa, sementara Steelhead secara transparan mengoptimasi dan mengakselerasi setiap komunikasi yang terjadi.
Tiap optimized flow terdiri atas 3 koneksi unik TCP, dan koneksinya pun 1 to 1.
Posisi Server dan Client tergantung siapa yang mengirim SYN duluan. Sisi yang mengirimkan SYN duluan maka akan bertindak sebagai client. Pada saat yang sama, bisa saja dia bertindak sebagai server juga karena mendapatkan SYN dari sisi lainnya. Harus ada SYN dulu baru ada optimized flow
Posisi Menentukan Prestasi!
SSH : Server Steelhead : yang memberikan jawaban atas request dari Requestor dan CSH
CSH : Client Steelhead : yang meminta data dari SSH

Transaction Acceleration (TA)
TA : SDR + VWE + TP
TA terdiri atas mekanisme optimasi sebagai berikut:
- Mekanisme untuk mengurangi pemakaian bandwidth yang disebut Scalable Data Referencing (SDR)
- Mekanisme Virtual TCP Window Expansion (VWE) yang membungkus paket TCP dengan referensi yang mewakili jumlah dan data
- Mekanisme untuk mengurangi dan menghindari latensi yang disebut Transaction Prediction (TP). Mekanisme ini bekerja pada layer 7 (layer aplikasi pada OSI Layer). Sehingga tiap paket yang datang, jika layer 7 mengetahui jenis aplikasi ini, layer 7 akan mengoptimasinya lebih baik.
SDR dan TP dapat digunakan sendiri-sendiri atau secara bersamaan, tergantung karakteristik dan banyaknya data yang dikirim melewati jaringan. Hasil dari proses optimasi dapat bervariasi tetapi biasanya terlihat pada throughput yang meningkat antara 10-100 kali dari throughput link yang tidak dioptimasi.
Scalable Data Referencing (SDR)
Scalable Data Referencing (SDR) Menanggulangi Keterbatasan Bandwidth
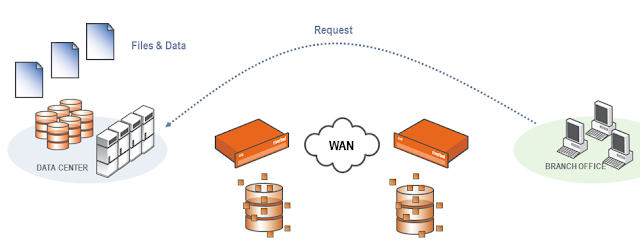
Permintaan langsung dari client ke server, tanpa diproses oleh Steelhead
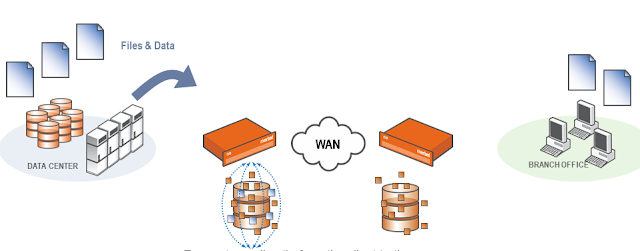
Saat server merespons, Steelhead terdekat dengan server akan auto-intercepts respons tersebut lalu mengubahnya menjadi data segment data dan menyimpannya di penyimpanan data perangkat.
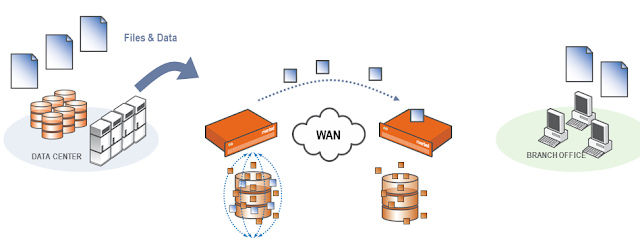
Hanya byte baru yang dikompresi dengan LZ Compression dan dikirimkan melalui WAN.

Remote Steelhead merekonstruksi data tersebut dan mengirimkannya ke client yang pertama kali mengirim SYN.

Jika data yang sama dikirimkan, maka perangkat di sisi terdekat akan mengenali bahwa data tersebut telah pernah di SYN sebelumnya dan hanya akan mengirimkan referensi sebesar 16 Byte.
Data sebesar 128 byte (128 Byte sebesar ukuran 1 potongan data/chunk) atau lebih direpresentasikan oleh referensi sebesar 16 Byte saja. Hal ini bisa menghasilkan 80-90% reduksi data.

Bentuk hierarki digunakan juga untuk memecah dari potongan data yang besar (super chunk) dan redundant serta merepresentasikannya menjadi referensi tunggal (single reference). Satu super reference dapat merefer ke beberapa referensi lagi. Contoh gampangnya adalah, jika salah satu bagian dari suatu file digunakan pada file yang lain, walaupun formatnya berbeda, maka Steelhead tetap dapat mengenalinya. Misalnya suatu gambar awalnya ada di file PPT, lalu dicopy ke file Word, maka Steelhead tetap dapat mengenalinya sebagai data redundant dan mencari referensinya
Slide Note:
Bandwidth optimization dihasilkan dari SDR. SDR menggunakan algoritma khusus untuk memecah data stream TCP menjadi data chunk yang disimpan di hard disk (data store – penyimpanan data) dari perangkat Riverbed. Tiap potongan data ditempelkan label integer yang unik (reference) sebelum dikirim ke peer Steelhead melalui WAN. Jika urutan byte yang dikirimkan terlihat lagi di TCP data stream, maka yang dikirimkan melalui WAN hanya referensinya saja, bukan file aslinya. Referensi ini digunakan oleh perangkat Riverbed untuk merekonstruksi data chunk TCP data stream aslinya. Data dan referensi disimpan di tempat penyimpanan dalam data store perangkat Riverbed.
Bagaimana SDR bekerja?
Saat data dikirimkan pertama kali melalui jaringan (tidak ada kesamaan dengan file yang sudah dikirimkan sebelumnya), semua data dan referensi statusnya baru sehingga seluruh data dan referensi tersebut dikirimkan ke perangkat Steelhead yang berada di jaringan seberangnya. Data baru ini beserta referensi yang menyertainya tetap dikompresi menggunakan algoritma konvensional untuk meningkatkan performa, meskipun pada transfer pertama.
Ketika data berubah, dibuatlah data dan referensi yang baru. Sehingga kapanpun permintaan baru dikirimkan melalui jaringan, referensi yang dibuat tadi akan dibandingkan dengan referensi yag ada di penyimpanan data perangkat Riverbed lokal. Jika ada data yang ternyata pernah dikirimkan sebelumnya, maka data yang sudah ada di tersebut tidak akan dikirimkan kembali, hanya referensinya yang akan dikirim melalui jaringan WAN.
Pembaruan dan penambahan referensi data terus menerus dilakukan di data store perangkat Riverbed selaras dengan semakin banyak data yang diproses (dikirim, disalin, diedit, dipindahkan dan lain-lain). Referensi dapat dipakai bersama oleh file yang berbeda, bahkan file di aplikasi yang berbeda jika bit-bit penyusunnya serupa. Karena SDR dapat beroperasi di semua protokol berbasis TCP, keserupaan data disemua protokol dapat dimanfaatkan sepanjang representasi biner dari data tersebut tidak berubah antar protokol. Sebagai contoh, jika file ditransfer via FTP dan kemudian ditransfer menggunakan WFS (Windows File System), representasi biner dari file pada dasarnya sama dan karena itu referensi dapat dikirim untuk data tersebut.
Universal Data Store
- SDR menyimpan chunk (potongan) data yang disebut segment di penyimpanan data
- Tidak tergantung pada protokol aplikasi, port interface atau peer
- Penyimpanan data yang FULL adalah normal. “Wrap” time mengacu pada segment paling awal (paling pertama)
- Model penggusuran default adalah berdasarkan model Least Recently Used (LRU), dimana data yang paling sedikit dipakai referensinya akan dihapus saat diperlukan ruang kosong untuk data yang baru.
- Dapat juga dikonfigurasi model FIFO (First In First Out) eviction, dimana data yang paling awal masuk yang akan dihapus duluan, tanpa memperhitungkan apakah data tersebut banyak referensinya atau tidak.
Kebanyakan dari kompetitor Riverbed (klaim dari Riverbed) tidak menggunakan penyimpanan data mereka secara efisien. Masalah yang mereka miliki terkait dengan penyimpanan data adalah:
Per Peer Data Store – Ada penyimpanan data yang terpisah antar remote site. Jadi jika ada Data Center dan 5 remote site, jadi DC WAN Optim memiliki pola data (data pattern) yang tersimpan sebanyak 50x, 1 di tiap remote site.
Caches – Cache menyimpan data pada beberapa area yang berbeda di disk. Jadi bisa saja satu pola dari suatu file tersimpan di satu bagian disk, namun bagian lain tersimpan di tempat yang berbeda dalam disk tersebut.
Data Transfer Terminology
- Warm Transfer adalah transfer suatu data yang sudah pernah ditransfer sebelumnya. Memanfaatkan segmen yang telah tersimpan pada penyimpanan data kedua perangkat Steelhead yang terlibat komunikasi.
- Cold Transfer adalah data yang belum pernah diterima sebelumnya oleh kedua perangkat Steelhead yang berkomunikasi.
- Partial Warm Transfer adalah data yang hanya ada sebagian saja di kedua penyimpanan data perangkat Steelhead.
SDR Flavors (Adaptive Data Streamlining)
- Default
- Penyimpanan data menggunakan piringan disk
- Reduksi bandwidth (BW) yang sangat baik. Dikarenakan ukuran penyimpanan disk relatif sangat besar, sehingga lebih banyak data dan referensi yang bisa disimpan, sehingga tidak perlu terlalu sering mengirimkan data yang sama berulangkali. Kelebihan lainnya adalah non-volatile, sehingga walaupun sistem restart data yang tersimpan tetap aman, namun karena ukurannya besar, proses pembacaan data menjadi lebih lama.
- SDR-M
- Penyimpanan data berdasarkan RAM
- Throughput di sisi LAN sangat baik. Karena proses pembacaan RAM lebih cepat dibandingkan pembacaan harddisk. Kelemahannya adalah volatile, jika sistem restart, maka isi dari RAM akan hilang.
- SDR-Adaptive
- Penggabungan data store/compression model
- Memonitor proses respon pembacaan dan penulisan disk I/O, berdasarkan statistik trend, dapat menggunakan campuran teknik reduksi data disk based dan non disk based yang memungkinkan throughput berkelanjutan selama periode dimana beban kerja harddisk sangat tinggi.
- Sangat baik dari sisi LAN side throughput dan BW reduction
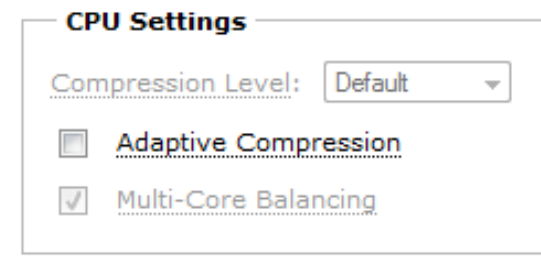
Adaptive Compression
Dapat diakses di menu : Configure > Optimization > Performance
Mendeteksi performansi data kompresi LZ dari sebuah koneksi secara dinamis dan mematikannya (mengeset nilai level kompresi ke 0) sesaat jika kompresi tidak optimal (bisa jadi karena data yang dikirimkan sudah dikompresi dan/atau dienkripsi). Meningkatkan end to end throughput melalui LAN dengan memaksimalkan throughput WAN. Secara default, pengaturan ini dinonaktifkan.